


Avec cette édition, nous inaugurons une chronique intitulée, « Autour des mots », qui sera régulièrement animée par notre collaborateur Ousmane Sawadogo, Expert-consultant en « Text Mining » et « Web Content Mining », approximativement en Français, « Analyste du discours ». Que révèlent les mots que nous utilisons pour évoquer certains sujets, parler des groupes d’individus ou des catégories de personnes ? Décryptage.
Quand les gentilés « africain(e)s », « asiatiques », « indien(ne)s », « américain(e)s » et européen(ne)s apparaissent dans les titrages…
A quoi sont associés les gentilés (dénomination des habitants d’un lieu) « africain(e)s » (sans « sud-africain(e)s »), « asiatique(s) », « indien(ne)s », « américain(e)s » et « européen(ne)s » quand ils apparaissent dans les titres d’articles francophones sur le Web ? Dit autrement, comment se configurent les univers sémantiques associés à ces gentilés, adjectifs et noms relatifs à l’Afrique, à l’Asie, à l’Inde et/ou au sous-continent indien, aux Amériques, à l’Europe, à leurs peuples respectifs, leurs langues et leurs cultures ?
Pour tenter d’apporter une réponse possible à ce questionnement, nous avons constitué cinq (5) corpus de titres d’articles francophones publiés sur le Web : corpus « africain », corpus « asiatique », corpus « indien », corpus « américain » et corpus « européen ». Chaque corpus regroupe environ 10 000 titres pertinents, recueillis grâce aux archives de Google sur dix ans (2006-2015).
L’analyse du contenu sémantique de ces cinq corpus de titres nous a permis d’identifier neuf (09) groupes de références sémantiques associés, relatifs à l’art, la culture et l’éducation/formation qui méritent attention : « cuisine et restauration », « musique, chants, chansons », « artisanat » (sculpture, statuettes, masques…), « littérature » (romans, contes, poésie, proverbes…), « vêtements, tissus, chaussures », « cinéma », les « arts de la scène » (spectacles, danse, chorégraphie, théâtre, festival…), « histoire, philosophie, langue, religion », et « éducation, formation ».
Ainsi que le montrent les graphiques, les cinq corpus de titres présentent les saillances suivantes :
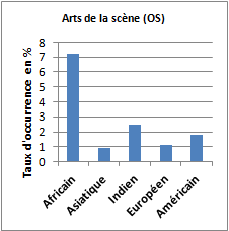
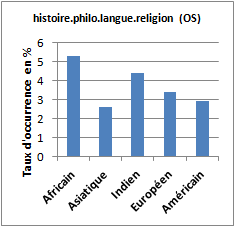
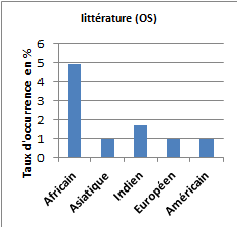
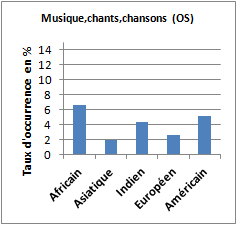
Le corpus « africain » se singularise par la saillance des groupes de références sémantiques tels : « musique, chants, chansons » ; « arts de la scène » (spectacle, danse, théâtre, chorégraphie, marionnettes…) ; « littérature » (romans, poésie, contes, proverbes…) et « histoire, philosophie, langue, religion ». Ces quatre groupes de références sémantiques sont significativement plus présents dans le corpus de titres d’articles où le terme « africain(e)s » apparaît que dans les quatre autres corpus. On notera tout de même que les corpus « américain » et « indien » présentent aussi des références importantes à la catégorie sémantique « musique, chants, chanson ».
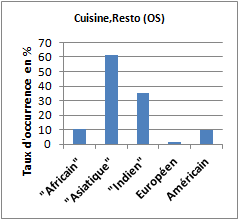
Le corpus « asiatique » se distingue par une saillance du groupe de références sémantiques « cuisine, restauration ». Sur ce sujet, il est suivi du corpus « indien ».
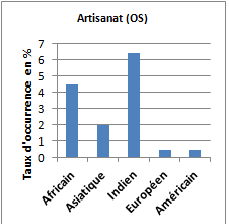
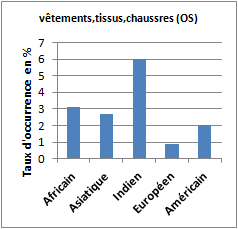
Le corpus « indien » se démarque par les saillances de deux groupes de références sémantiques : « vêtements, tissus, chaussures » et « artisanat » (sculptures, masques, statuettes, figurines, bijoux…). Sur ce sujet de l’artisanat, on note aussi que le corpus « africain » en est imprégné de façon relativement importante.
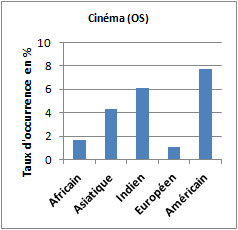
Le corpus « américain » se singularise par la saillance du groupe sémantique « cinéma » (cinéma, film, hollywood, bollywood… ». On note tout de même que les taux d’occurrence de la catégorie sémantique « cinéma » dans les corpus « indien » et « asiatique » sont aussi relativement importants.
Enfin, le corpus « européen » est marqué par une nette saillance du groupe de références sémantiques « éducation, formation ».
Ces résultats donnent une sorte de photographie couvrant l’ensemble de la décennie 2006-2015. Pour celles et ceux qui sont intéressés à regarder l’évolution de ces résultats dans ledit temps décennal, bien vouloir contacter notre Webmaster.

Ousmane SAWADOGO, Expert-Consultant en « Text Mining » et « Web Content Mining ».
Kaceto.net














Recent Comments
Un message, un commentaire ?